 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebyte n-gram
Papers and Code
Zonkey: A Hierarchical Diffusion Language Model with Differentiable Tokenization and Probabilistic Attention
Jan 29, 2026Large language models (LLMs) have revolutionized natural language processing, yet they remain constrained by fixed, non-differentiable tokenizers like Byte Pair Encoding (BPE), which hinder end-to-end optimization and adaptability to noisy or domain-specific data. We introduce Zonkey, a hierarchical diffusion model that addresses these limitations through a fully trainable pipeline from raw characters to document-level representations. At its core is a differentiable tokenizer (Segment Splitter) that learns probabilistic beginning-of-sequence (BOS) decisions, enabling adaptive splits that emerge as linguistically meaningful (e.g., word boundaries at spaces, sentence starts at periods) without explicit supervision. This differentiability is enabled by our novel Probabilistic Attention mechanism, which incorporates position-specific existence probabilities to simulate soft masking over theoretically infinite sequences while preserving gradients. Sequences decay probabilistically rather than relying on end-of-sequence tokens, supporting variable-length outputs. Hierarchical levels compress sequences into higher abstractions (e.g., character n-grams to word-like vectors, then sentence-like), with reconstruction via our Denoising Diffusion Mixed Model (DDMM) for stable and efficient denoising in latent space. A Stitcher ensures overlap invariance across segments. Trained end-to-end on Wikipedia, Zonkey generates coherent, variable-length text from noise, demonstrating emergent hierarchies and promising qualitative alignment to data distributions compared to entropy-based learnable tokenizers. Our approach advances toward fully gradient-based LLMs, with potential for better domain adaptation and scalable generation. We release the source code for training and reproducing our experiments.
Zipf-Gramming: Scaling Byte N-Grams Up to Production Sized Malware Corpora
Nov 17, 2025A classifier using byte n-grams as features is the only approach we have found fast enough to meet requirements in size (sub 2 MB), speed (multiple GB/s), and latency (sub 10 ms) for deployment in numerous malware detection scenarios. However, we've consistently found that 6-8 grams achieve the best accuracy on our production deployments but have been unable to deploy regularly updated models due to the high cost of finding the top-k most frequent n-grams over terabytes of executable programs. Because the Zipfian distribution well models the distribution of n-grams, we exploit its properties to develop a new top-k n-gram extractor that is up to $35\times$ faster than the previous best alternative. Using our new Zipf-Gramming algorithm, we are able to scale up our production training set and obtain up to 30\% improvement in AUC at detecting new malware. We show theoretically and empirically that our approach will select the top-k items with little error and the interplay between theory and engineering required to achieve these results.
* Published in CIKM 2025
A Byte Sequence is Worth an Image: CNN for File Fragment Classification Using Bit Shift and n-Gram Embeddings
Apr 14, 2023File fragment classification (FFC) on small chunks of memory is essential in memory forensics and Internet security. Existing methods mainly treat file fragments as 1d byte signals and utilize the captured inter-byte features for classification, while the bit information within bytes, i.e., intra-byte information, is seldom considered. This is inherently inapt for classifying variable-length coding files whose symbols are represented as the variable number of bits. Conversely, we propose Byte2Image, a novel data augmentation technique, to introduce the neglected intra-byte information into file fragments and re-treat them as 2d gray-scale images, which allows us to capture both inter-byte and intra-byte correlations simultaneously through powerful convolutional neural networks (CNNs). Specifically, to convert file fragments to 2d images, we employ a sliding byte window to expose the neglected intra-byte information and stack their n-gram features row by row. We further propose a byte sequence \& image fusion network as a classifier, which can jointly model the raw 1d byte sequence and the converted 2d image to perform FFC. Experiments on FFT-75 dataset validate that our proposed method can achieve notable accuracy improvements over state-of-the-art methods in nearly all scenarios. The code will be released at https://github.com/wenyang001/Byte2Image.
byteSteady: Fast Classification Using Byte-Level n-Gram Embeddings
Jun 24, 2021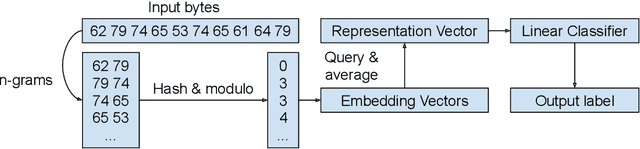
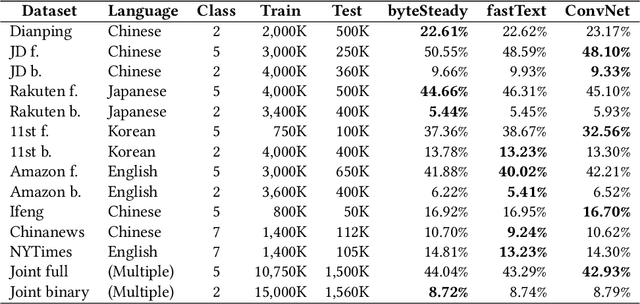

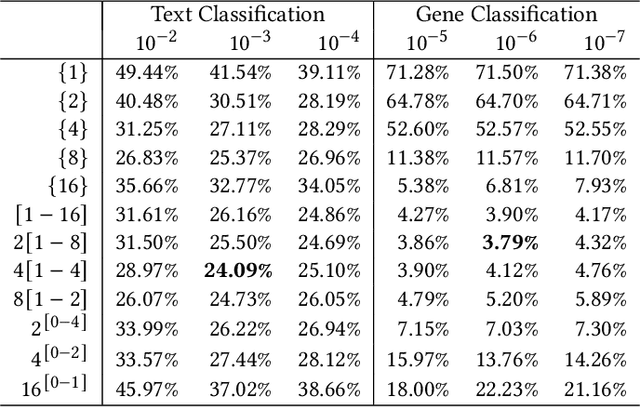
This article introduces byteSteady -- a fast model for classification using byte-level n-gram embeddings. byteSteady assumes that each input comes as a sequence of bytes. A representation vector is produced using the averaged embedding vectors of byte-level n-grams, with a pre-defined set of n. The hashing trick is used to reduce the number of embedding vectors. This input representation vector is then fed into a linear classifier. A straightforward application of byteSteady is text classification. We also apply byteSteady to one type of non-language data -- DNA sequences for gene classification. For both problems we achieved competitive classification results against strong baselines, suggesting that byteSteady can be applied to both language and non-language data. Furthermore, we find that simple compression using Huffman coding does not significantly impact the results, which offers an accuracy-speed trade-off previously unexplored in machine learning.
How Effective is Byte Pair Encoding for Out-Of-Vocabulary Words in Neural Machine Translation?
Aug 17, 2022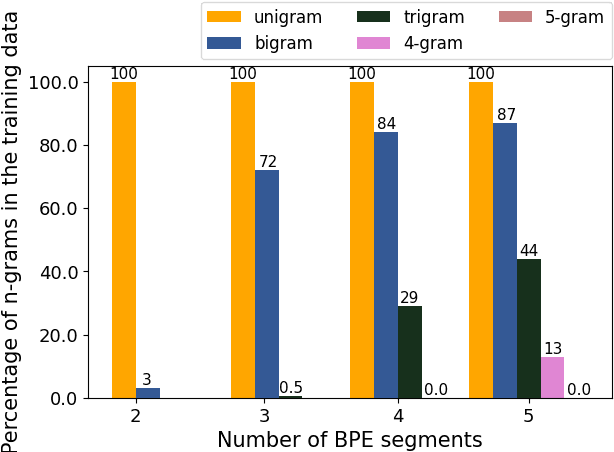
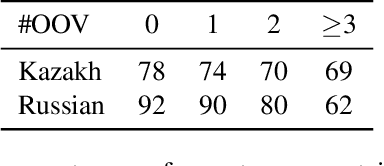
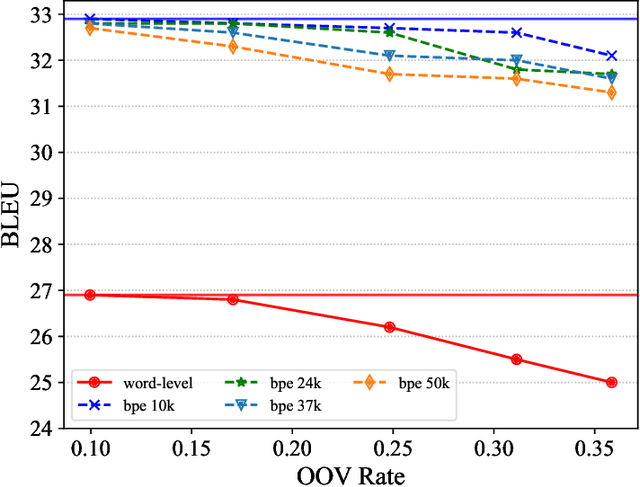
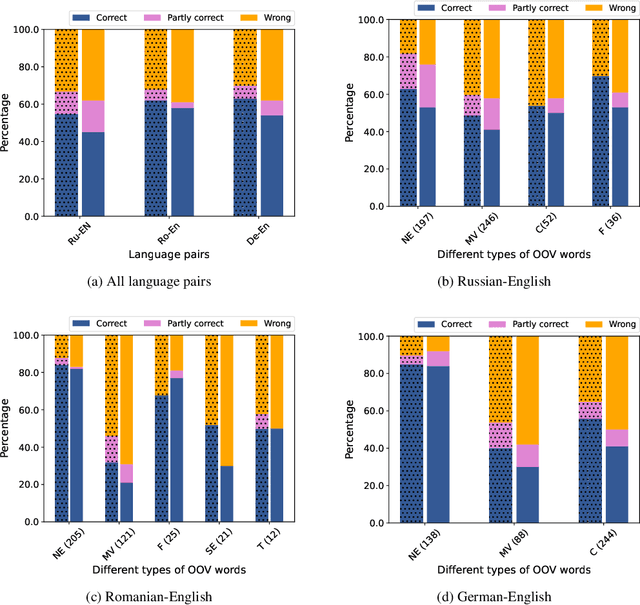
Neural Machine Translation (NMT) is an open vocabulary problem. As a result, dealing with the words not occurring during training (a.k.a. out-of-vocabulary (OOV) words) have long been a fundamental challenge for NMT systems. The predominant method to tackle this problem is Byte Pair Encoding (BPE) which splits words, including OOV words, into sub-word segments. BPE has achieved impressive results for a wide range of translation tasks in terms of automatic evaluation metrics. While it is often assumed that by using BPE, NMT systems are capable of handling OOV words, the effectiveness of BPE in translating OOV words has not been explicitly measured. In this paper, we study to what extent BPE is successful in translating OOV words at the word-level. We analyze the translation quality of OOV words based on word type, number of segments, cross-attention weights, and the frequency of segment n-grams in the training data. Our experiments show that while careful BPE settings seem to be fairly useful in translating OOV words across datasets, a considerable percentage of OOV words are translated incorrectly. Furthermore, we highlight the slightly higher effectiveness of BPE in translating OOV words for special cases, such as named-entities and when the languages involved are linguistically close to each other.
Malware Detection Using Frequency Domain-Based Image Visualization and Deep Learning
Jan 26, 2021
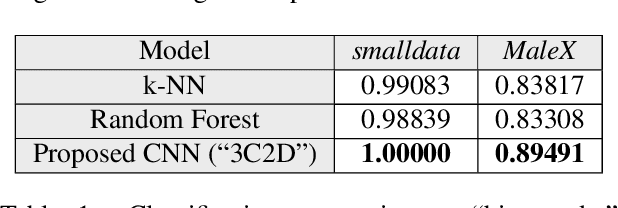

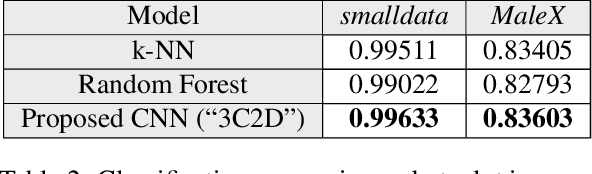
We propose a novel method to detect and visualize malware through image classification. The executable binaries are represented as grayscale images obtained from the count of N-grams (N=2) of bytes in the Discrete Cosine Transform (DCT) domain and a neural network is trained for malware detection. A shallow neural network is trained for classification, and its accuracy is compared with deep-network architectures such as ResNet that are trained using transfer learning. Neither dis-assembly nor behavioral analysis of malware is required for these methods. Motivated by the visual similarity of these images for different malware families, we compare our deep neural network models with standard image features like GIST descriptors to evaluate the performance. A joint feature measure is proposed to combine different features using error analysis to get an accurate ensemble model for improved classification performance. A new dataset called MaleX which contains around 1 million malware and benign Windows executable samples is created for large-scale malware detection and classification experiments. Experimental results are quite promising with 96% binary classification accuracy on MaleX. The proposed model is also able to generalize well on larger unseen malware samples and the results compare favorably with state-of-the-art static analysis-based malware detection algorithms.
Low-Resource Language Modelling of South African Languages
Apr 01, 2021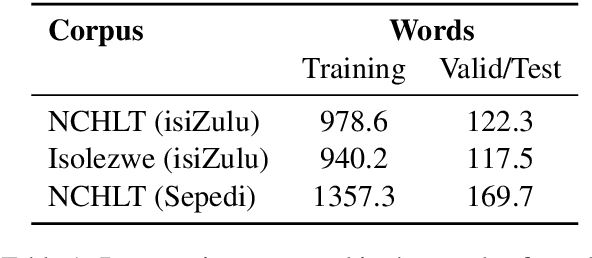
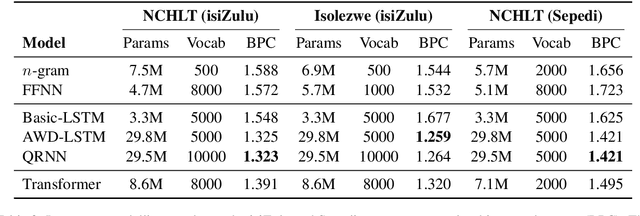
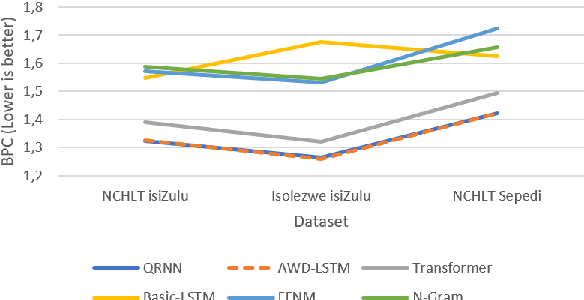
Language models are the foundation of current neural network-based models for natural language understanding and generation. However, research on the intrinsic performance of language models on African languages has been extremely limited, which is made more challenging by the lack of large or standardised training and evaluation sets that exist for English and other high-resource languages. In this paper, we evaluate the performance of open-vocabulary language models on low-resource South African languages, using byte-pair encoding to handle the rich morphology of these languages. We evaluate different variants of n-gram models, feedforward neural networks, recurrent neural networks (RNNs), and Transformers on small-scale datasets. Overall, well-regularized RNNs give the best performance across two isiZulu and one Sepedi datasets. Multilingual training further improves performance on these datasets. We hope that this research will open new avenues for research into multilingual and low-resource language modelling for African languages.
Adversarially-Trained Normalized Noisy-Feature Auto-Encoder for Text Generation
Nov 10, 2018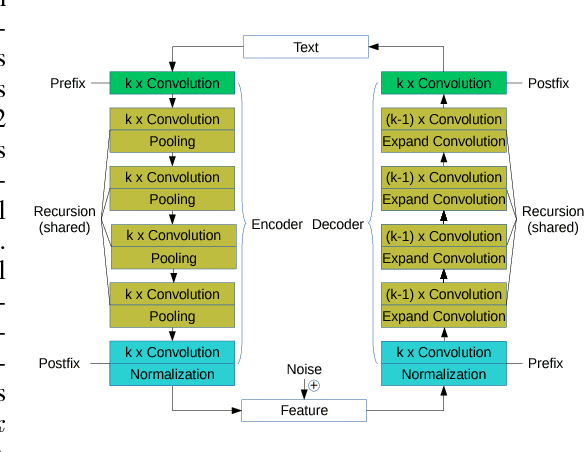
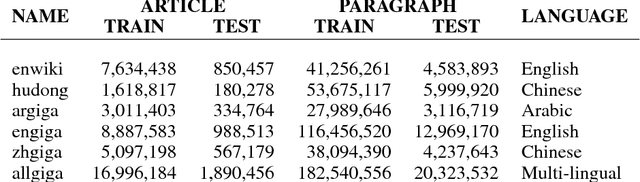
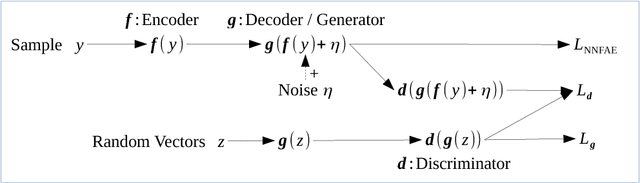
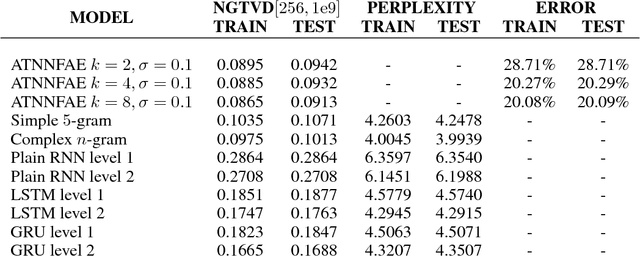
This article proposes Adversarially-Trained Normalized Noisy-Feature Auto-Encoder (ATNNFAE) for byte-level text generation. An ATNNFAE consists of an auto-encoder where the internal code is normalized on the unit sphere and corrupted by additive noise. Simultaneously, a replica of the decoder (sharing the same parameters as the AE decoder) is used as the generator and fed with random latent vectors. An adversarial discriminator is trained to distinguish training samples reconstructed from the AE from samples produced through the random-input generator, making the entire generator-discriminator path differentiable for discrete data like text. The combined effect of noise injection in the code and shared weights between the decoder and the generator can prevent the mode collapsing phenomenon commonly observed in GANs. Since perplexity cannot be applied to non-sequential text generation, we propose a new evaluation method using the total variance distance between frequencies of hash-coded byte-level n-grams (NGTVD). NGTVD is a single benchmark that can characterize both the quality and the diversity of the generated texts. Experiments are offered in 6 large-scale datasets in Arabic, Chinese and English, with comparisons against n-gram baselines and recurrent neural networks (RNNs). Ablation study on both the noise level and the discriminator is performed. We find that RNNs have trouble competing with the n-gram baselines, and the ATNNFAE results are generally competitive.
Learning the PE Header, Malware Detection with Minimal Domain Knowledge
Nov 11, 2017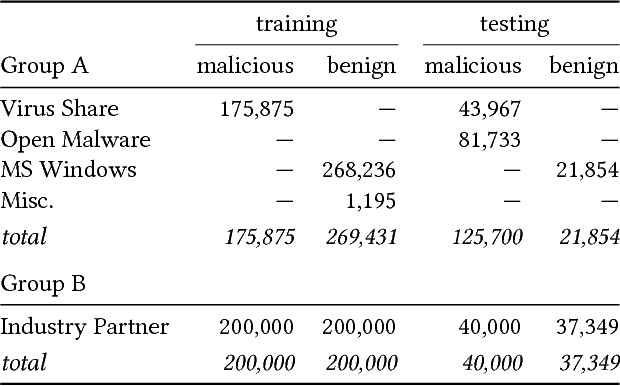
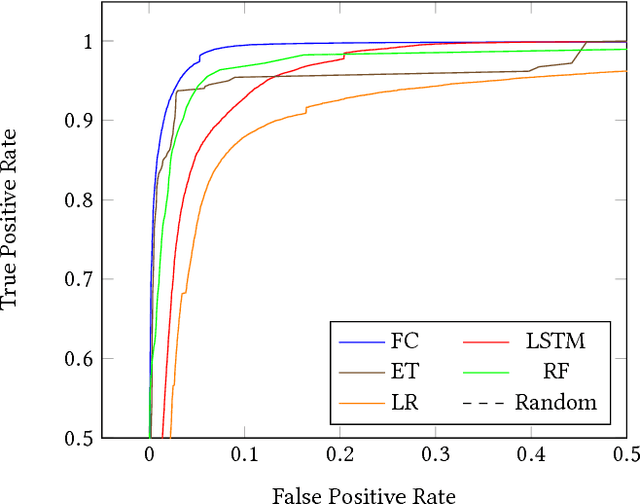

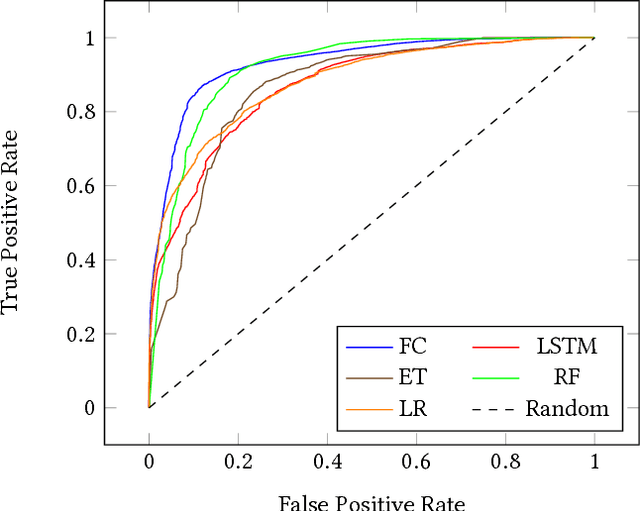
Many efforts have been made to use various forms of domain knowledge in malware detection. Currently there exist two common approaches to malware detection without domain knowledge, namely byte n-grams and strings. In this work we explore the feasibility of applying neural networks to malware detection and feature learning. We do this by restricting ourselves to a minimal amount of domain knowledge in order to extract a portion of the Portable Executable (PE) header. By doing this we show that neural networks can learn from raw bytes without explicit feature construction, and perform even better than a domain knowledge approach that parses the PE header into explicit features.
DLGNet: A Transformer-based Model for Dialogue Response Generation
Sep 04, 2019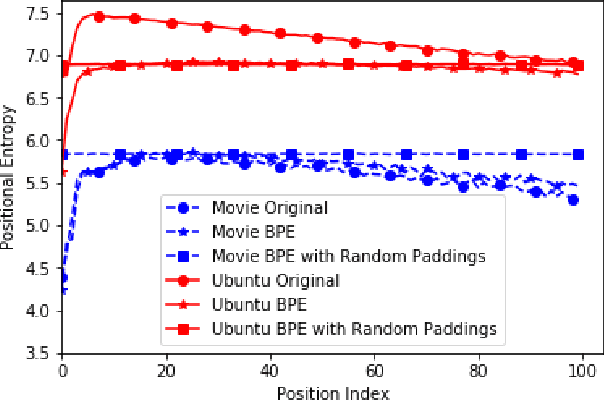
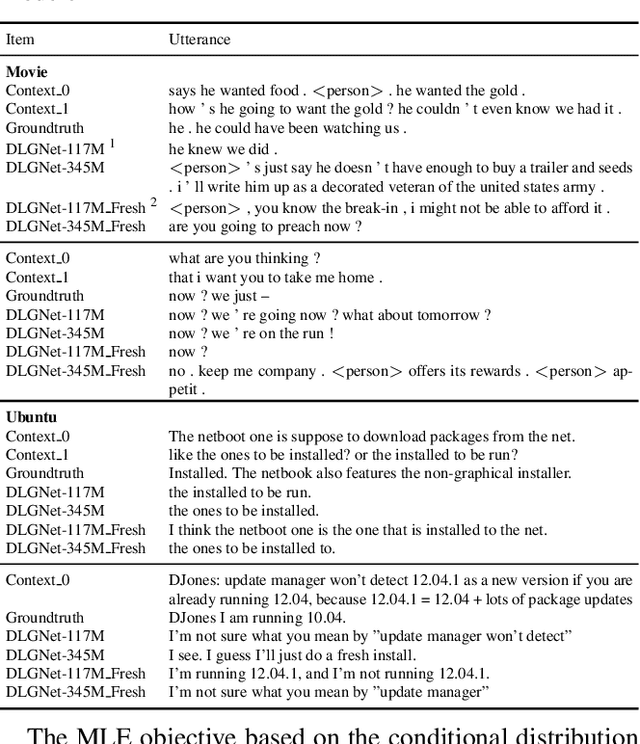
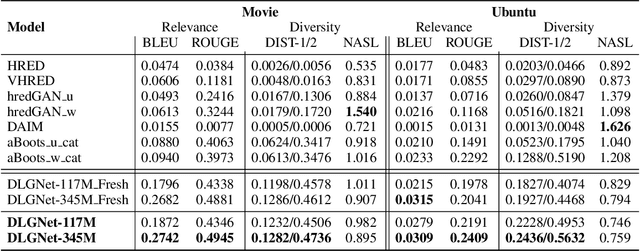
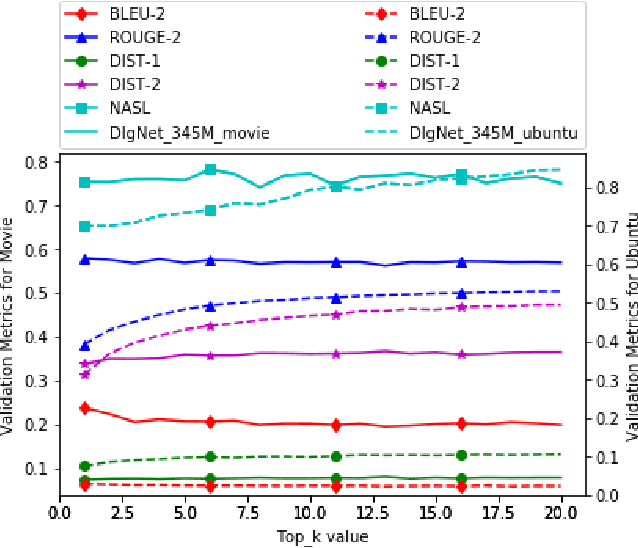
Neural dialogue models, despite their successes, still suffer from lack of relevance, diversity, and in many cases coherence in their generated responses. These issues can attributed to reasons including (1) short-range model architectures that capture limited temporal dependencies, (2) limitations of the maximum likelihood training objective, (3) the concave entropy profile of dialogue datasets resulting in short and generic responses, and (4) the out-of-vocabulary problem leading to generation of a large number of <UNK> tokens. On the other hand, transformer-based models such as GPT-2 have demonstrated an excellent ability to capture long-range structures in language modeling tasks. In this paper, we present DLGNet, a transformer-based model for dialogue modeling. We specifically examine the use of DLGNet for multi-turn dialogue response generation. In our experiments, we evaluate DLGNet on the open-domain Movie Triples dataset and the closed-domain Ubuntu Dialogue dataset. DLGNet models, although trained with only the maximum likelihood objective, achieve significant improvements over state-of-the-art multi-turn dialogue models. They also produce best performance to date on the two datasets based on several metrics, including BLEU, ROUGE, and distinct n-gram. Our analysis shows that the performance improvement is mostly due to the combination of (1) the long-range transformer architecture with (2) the injection of random informative paddings. Other contributing factors include the joint modeling of dialogue context and response, and the 100% tokenization coverage from the byte pair encoding (BPE).